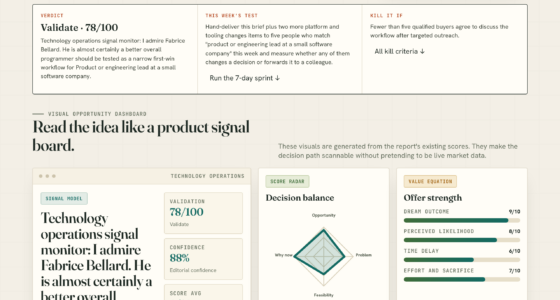
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry is facing a new bottleneck: data that cannot be rented or scraped freely. As public datasets dry up and legal restrictions tighten, the focus shifts to rare, verified data behind paywalls and in expert hands, reshaping industry dynamics.
Data has become the last unrentable asset in AI training, as industry shifts away from free web scraping toward licensed and exclusive sources. This change, confirmed by recent legal settlements and industry moves, significantly impacts how AI models are trained and who can afford to compete in the field.
In 2026, the industry has largely exhausted the free, public datasets used for training AI models, with estimates suggesting the public internet holds around 300 trillion tokens of high-quality text. According to Epoch AI, the stock of available human-generated data is projected to be fully utilized between 2026 and 2032, with a median around 2028. This scarcity has led to increased reliance on synthetic data, which, while useful, carries risks of model collapse if overused in domains where answers are hard to verify.
Legal actions have marked a turning point: Anthropic’s $1.5 billion settlement with authors over copyright violations signals the end of the era of free scraping. Learn more about recent AI-related legal shifts. The court’s ruling clarified that training on legally acquired texts is fair use, but piracy and shadow library downloads are not, leading to industry-wide shifts toward licensing models. Major publishers like The New York Times are now moving from lawsuits to licensing agreements, making data access more expensive and concentrated among well-funded players.
Simultaneously, the industry is experiencing a shift in the nature of valuable data. The focus has moved from cheap, web-scraped content to rare, verified, human-authored data—such as proprietary annotations from combat drones or specialized expert input—creating new industry chokepoints. Companies like Meta, Surge, and Mercor are leveraging exclusive data sources and expertise, which act as barriers to entry for smaller players.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Implications of Data Fencing for AI Industry Competition
The shift toward fencing and licensing of data consolidates industry power among large incumbents who can afford costly datasets and legal compliance. Smaller startups face increasing barriers, potentially reducing innovation and diversity in AI development. Moreover, reliance on rare, verified data emphasizes the importance of expertise and proprietary sources, reshaping the competitive landscape and raising questions about data access and fairness in AI progress.
AI training data licensing services
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Changes Reshaping Data Access
Historically, AI training depended heavily on freely available web data, with companies scraping content without significant legal repercussions. However, legal cases like Anthropic’s $1.5 billion settlement and ongoing lawsuits by publishers have established a precedent: data used for training now faces licensing costs and legal restrictions. This has led to a market where data is increasingly treated as a paid asset, favoring large firms with resources to secure licensed and exclusive datasets. The industry is also witnessing a transition from cheap, web-scraped data to rare, expert-generated content, as models require more specialized, verified inputs for reasoning and complex tasks.
“The court’s ruling clarifies that fair use applies to legally acquired texts, but piracy and shadow libraries are off-limits, marking a new legal landscape for AI data.”
— Legal expert involved in the Anthropic case
verified human-made data datasets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unclear Aspects of Future Data Access and Industry Impact
It remains uncertain how quickly smaller players can adapt to increased licensing costs and whether new proprietary data sources will be sufficient to sustain innovation at the current pace. The long-term effects of legal restrictions and market concentration are still developing, and the potential for new data-sharing agreements or regulatory interventions is unknown.professional data annotation tools
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Data Market Evolution and Industry Adaptation
Industry players will likely continue to shift toward exclusive data partnerships, licensing agreements, and synthetic data innovations. Legal and regulatory developments may further shape data access policies, potentially leading to new industry standards or restrictions. Smaller firms may seek alternative data sources or focus on niche markets, while larger companies expand their proprietary datasets. Monitoring legal rulings and licensing trends will be crucial to understanding how data access evolves in the coming years.
exclusive data collection services
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why can’t data be rented like compute or power?
Data is inherently unique and often proprietary, especially when it involves verified, expert-generated, or copyrighted content. Unlike compute resources, which can be leased or rented, data cannot be easily duplicated or shared without legal or ethical considerations, making it a chokepoint that cannot be rented or freely exchanged.
What does the legal shift mean for AI startups?
The move toward licensing and legal restrictions increases entry costs for startups, favoring well-funded incumbents. Smaller companies may face barriers to access proprietary datasets, potentially limiting innovation and competition in the industry.
How does synthetic data fit into this new landscape?
Synthetic data is increasingly used to supplement training datasets, especially when real data is scarce or costly. However, overreliance on synthetic data can introduce risks of model inaccuracies, particularly in complex or verification-sensitive domains.
Will data fencing lead to monopolies in AI development?
Legal and market barriers to data access could concentrate power among large firms capable of paying licensing fees and securing exclusive datasets, potentially reducing competition and innovation from smaller players.
What might change in the future regarding data access?
Future developments could include new legal frameworks, data-sharing agreements, or industry standards that balance proprietary rights with open access, but the exact trajectory remains uncertain as the industry adapts to these legal and economic shifts.
Source: ThorstenMeyerAI.com