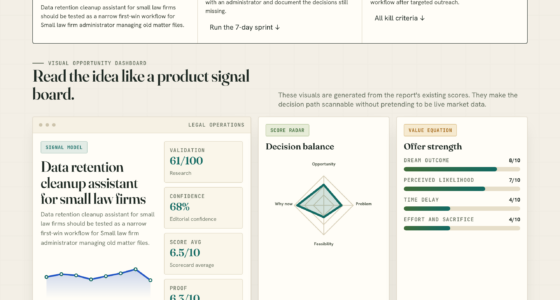

📊 Full opportunity report: Introducing Forezai · TradingAgents — a committee of LLMs decides paper-trades on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
Forezai has launched TradingAgents, a framework where a committee of large language models (LLMs) collaboratively generate paper-trading decisions. This development aims to explore AI’s potential in financial decision-making beyond traditional parametric strategies, emphasizing structured reasoning and multi-agent debate.
Forezai has launched a new version of the TradingAgents framework, enabling a committee of large language models (LLMs) to autonomously generate paper-trading decisions through structured debate and reasoning. This development marks a significant step in AI research aimed at understanding whether multi-agent LLM systems can outperform random decision-making in simulated trading environments.
The new project, called Forezai · TradingAgents, is a fork of an existing open-source framework that orchestrates multiple specialized LLMs to analyze market data and argue their respective positions. Unlike simple prediction models, this system involves thirteen distinct agent roles, including analysts focused on market structure, news, fundamentals, and social sentiment, as well as debate and risk assessment modules. The framework culminates in a final trading decision, expressed as a five-tier rating with price targets and time horizons.
Forezai’s implementation adds operational features such as an autonomous daily scheduler, paper trading via multiple broker interfaces (including Alpaca), position management, and a web dashboard for monitoring. Crucially, it runs entirely locally, with no risk of real-money trading unless explicitly overridden by the operator. The system is designed solely for research and testing, not live trading.
Introducing Forezai · TradingAgents.
A committee of LLMs
decides paper-trades.
Analysts · Debate · Risk · Decision
combined with -33% bankroll
services, HTTP routes (starting baseline)
(falls back to public API per token)
The bet is on a different mechanism, not a different parameter setting. The point is not to find a money-printing AI. The point is to put honest measurements of these systems into the public record — so the next person looking at the space starts a step further along than the last.Thorsten Meyer AI · Introducing Forezai · TradingAgents · § 03
Potential Impact on AI-Driven Market Research
This development is significant because it explores whether structured, multi-agent reasoning among LLMs can produce decision-making comparable or superior to random or rule-based strategies in simulated trading environments. If successful, it could influence future AI applications in financial analysis, emphasizing explicit reasoning and debate rather than prediction alone. However, it remains a research tool, and its effectiveness in real markets is unproven.

Premium Technical Analysis Quick Study/Flash Cards – Dive into Chart Patterns, Candlestick Patterns, and How to Spot and Trade Market Setups! Perfect for Investors and Day Traders at Any Skill Level.
- Includes 110 Flashcards: Covers essential trading concepts
- One Month Online Access: Exclusive trading platform access
- Suitable for All Skill Levels: For beginners and experts
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Background on AI and Trading Strategy Testing
Previous research by Thorsten Meyer and the TauricResearch team involved testing multi-strategy paper-trading bots like Polybot against prediction markets, revealing that many parametric strategies fail to survive real-world data, often appearing profitable in backtests but collapsing in live conditions. This highlighted the limitations of explicit rule-based approaches and raised questions about whether less rule-bound, reasoning-based AI systems could perform better.
The TradingAgents framework was developed to test this hypothesis by having multiple specialized LLMs argue their analyses, providing a more transparent and reasoned decision process. Forezai’s fork enhances this by adding operational features, making it suitable for systematic research rather than just theoretical exploration.
“The core idea is to see if a committee of LLMs, each with different biases and roles, can produce decisions that are at least no worse than random, given the same data a human would see.”
— Thorsten Meyer

AI-Assisted Trading for Retail Traders: A Disciplined Framework for Probability, Risk Control, and Structured Decision-Making
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Uncertainty About Real-World Effectiveness
It is not yet clear whether the reasoning and debate among LLMs will translate into meaningful trading advantages in live markets. The system currently operates only in simulated, paper-trading environments, and its performance in real trading conditions remains untested. Additionally, the impact of model biases, data quality, and system robustness are still unknown.
Context Engineering for Multi-Agent Systems: Move beyond prompting to build a Context Engine, a transparent architecture of context and reasoning
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Research and Development
Future work will involve extensive backtesting and live simulation to evaluate the decision-making quality of the TradingAgents system. Researchers plan to analyze the correlation between the system’s recommendations and actual market movements, as well as refine agent roles and reasoning strategies. Further, efforts will focus on integrating more sophisticated risk management and expanding the framework’s operational capabilities for broader testing.

SPREADSHEET LEDGER LIFE: How I Built Automated Portfolio Dashboards for U.S. Investors — From Bangladesh
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can Forezai TradingAgents be used for real trading?
No, the current system is designed solely for research and paper trading. It does not operate with real money unless deliberately configured and overridden by the user, which is not recommended without thorough testing.
How does the multi-agent system improve decision-making?
The system forces multiple specialized LLMs to analyze data and argue their positions, promoting explicit reasoning and debate. This contrasts with single prediction models and aims to reduce biases and improve robustness.
What are the main limitations of this approach?
The primary limitations include the lack of proven effectiveness in live markets, potential biases within LLMs, and the challenge of translating simulated decision-making into real-world gains. The system is still experimental and primarily for research purposes.
Will this technology replace human traders?
Currently, it is a research tool aimed at understanding AI decision-making processes. There is no indication that systems like Forezai TradingAgents will replace human traders but may complement analysis and decision support in the future.
Source: ThorstenMeyerAI.com